The meaningfulness of Events via standardization ( Part 4 )
In this part of the series, I'll focus on Filtering and Versioning optimization in EDA.
Some From The Past
In the previous parts, we focused on
Event Envelope
Promises
documenting
Validation
Filtering
Event Driven Design introduces some complexities in which without real attention to design we can introduce inconsistent and spaghetti design.
In this series, our principal focus is Event Driven Design on AWS.
To better start The Filtering let's start with a distributed design example.
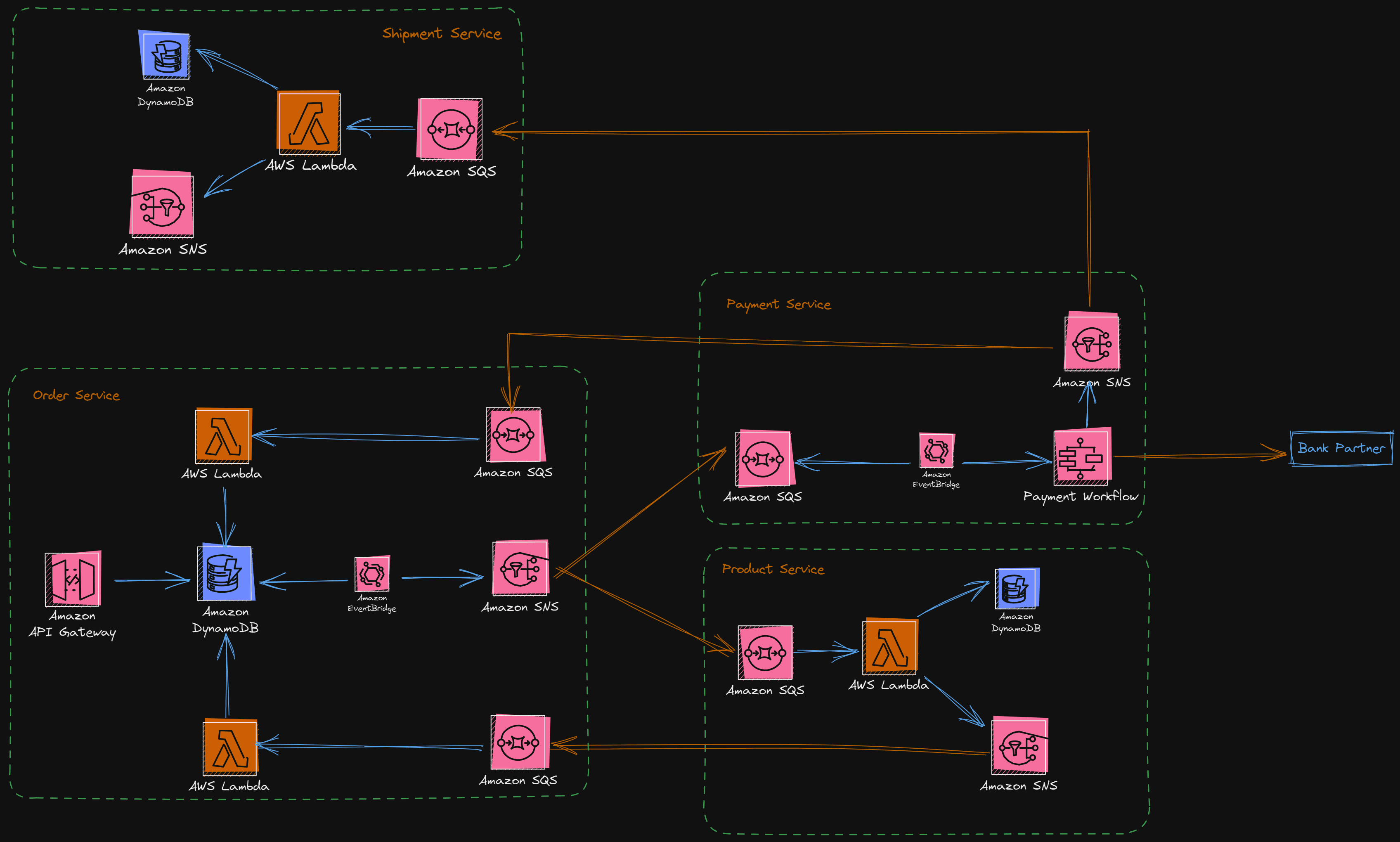
Scenario E-Commerce
The ordering system consists of the following components
Order Service
Payment Service
Product Service
Shipment Service
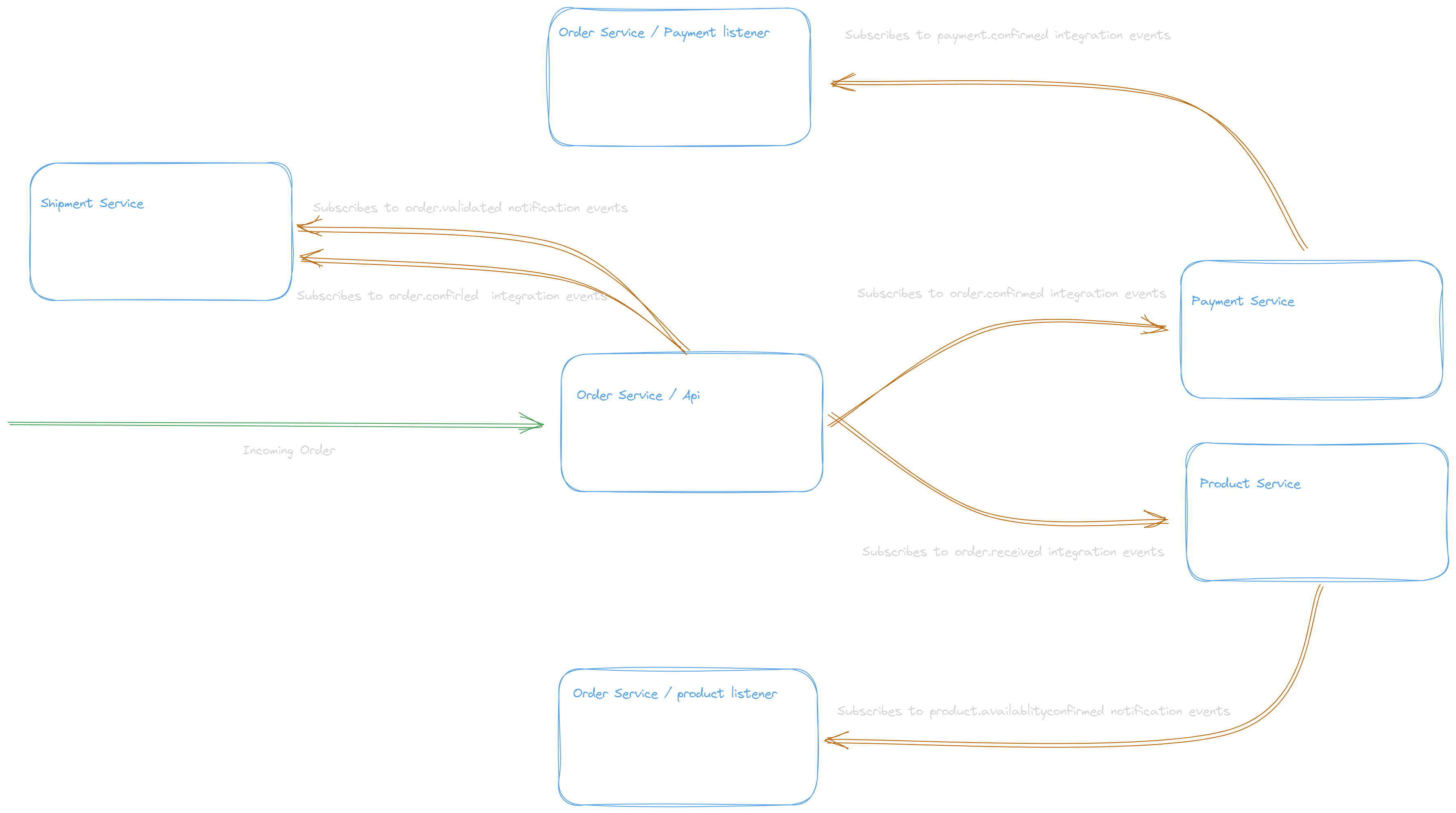
Here is the Four services architecture diagram
Successful order use case
Order Service receives >**Order Request
Order Service Sends Integration > 'order.received'
Product Service listens > 'order.received'
Product Service sends notification > 'product.availability-confirmed'
Order Service Sends integration > 'order.confirmed'
Shipment Service listens > 'order.confirmed'
Payment Service listens > 'order.confirmed'
Payment Service sends > 'payment.confirmed'
Order Service listens > 'payment.confirmed'
Order Service sends notification >**'order.validated'
Shipment Service listens > 'order.validated'
Shipment Service sends > 'shipment.delivered'
This design solves the order process and brings the following advantages
Decoupling
High Availability
Resiliency
Consistency
The Design has some disadvantages, we will refactor the design and try to improve it in the optimization part.
Challenges
The Order validation has some delay
The Design introduces some kind of Back-Forward communication
The Design can be hard to maintain because of the complexity
Communication
The components communicate in two ways as below
The payload of the Order received event
{
"spacVersion": "1.0.2",
"id": "2zz3DtEUvSYwCq8QauMFd",
"source": "ecommerce:order",
"type": "order.received",
"time": "2023-08-15T12:54:00.000Z",
"idempotencyKey": "e034f089-0829-5a58-902b-c3a7dc430778",
"correlationId": "1744cee7-8041-4f47-b744-a5ae60e96865",
"dataContentType": "application/json",
"dataSchema": "OrderIntegrationEvent#/components/schemas/OrderIntegrationEvent",
"dataVersion": "v1",
"data": {
"orderId": "MXAXFafccno71zHbXucpU",
"quantity": 3,
"price": 350,
"userId": "2trNCYr8y7zp9Ti4yWx"
}
}
The Product service subscribes to "order.received" integration event, here is the example of a subscription filter in Terraform
module "streaming_subscription" {
source = "../constructs/sns-sqs-subscription"
source_sns_topic_arn = var.producer_streaming_topic_arn
target_queue_arn = module.incoming_queue.queue_arn
target_queue_id = module.incoming_queue.queue_id
filter_policy_scope = "MessageBody"
filter_policy = jsonencode({
type: [ "order.received" ],
})
}
The rest of the configuration is emitted for brevity reasons, Source code example link here
In the above example, the Filtering is based on Event Context info and business event type, This way we can have multiple consumers on the same broker in which any consumer subscribes to its interested event type and category.
The producer pushes some events and the consumers receive those events and do some processing or treatment on their side.
A producer code snippet can be like below
const lambdaHandler: Handler = async (event: APIGatewayProxyEvent) : Promise<APIGatewayProxyResult> => {
const receivedCommandBody = JSON.parse(event.body)
const integration = EventEnvelope.createIntegrationEventEnvelope({
id: uuidv4(),
source: orderSource,
type: OrderEventType.Received,
data: generateEventData(receivedCommandBody)
});
await PublishEvent(integration);
}
Backward compatibility:
When it comes to inter-component communication in a distributed design one of the most important points to reveille is how to make changes fluent and avoid interruptions in the neighbourhood of boundaries.
Backward compatibility was introduced in early 2000 with the adoption of SOA by introducing software patterns like Round Robin, Format Change, Incremental, and Elimination practices. This became the hottest topic when the Microservice design was at the early stage of its adoption and by adopting the EDA and Async Design it became the hottest topic in most enterprises.
How to overcome the backward compatibility of Events?
In the above examples, we introduced some specific version attributes in which we presented the actual cloud event envelop version and the payload version to better let the consumers act behind the reception without impacting the producer model evolutions.
But let's see what are the different ways of doing versioning.
The dataversion attribute: This is a custom attribute introduced in this series just for the sake of brevity and less complexity, the dataversion represents the version of the event payload settled in data item, this helps the consumer to know the version in the early stage of consumption and rely on just the version based on its interest.
An example can be when the order received event data model evolves and the producer introduces a breaking change so the product service without caring about these changes must continue to process the incoming events.
Here the product system filtering policy
filter_policy = jsonencode({
type: [ "order.received" ],
dataversion: [ "v1" ]
})
This makes the filtering simple and guarantees the continuity of event delivery after introducing the other versions.
The type attribute: The type attribute can be an alternative and a better approach as it's part of CloudEvents Specification, sometimes Introducing the custom attributes is not desired for companies as it introduces an extra level of documentation and maintenance.
In this approach, the Producer can introduce the type of event including the version
{
...
"type": "order.received.v1",
....
}
The Consumer relies on the following filter policy.
filter_policy = jsonencode({
type: [ "order.received.v1" ]
})
This approach simplifies the standard but has some challenges
When it comes to filter policies the consumption relies on infrastructure features and in this approach, it becomes hard to filter for all "order.received" events agnostic of the event version, some brokers are allowing the prefix filtering but not all.
The data attribute: The other possibility is including the version inside data attribute as below.
{
...
"type": "order.received",
...
"data": {
"version": "v1"
...
}
}
This approach helps to attach the version to the data and reduce the complexity of the event envelope and the filtering complexity but removes the granularity to introduce different content types.
Most infrastructures rely on json filter policy and if in your enterprise there is a convention of using JSON as a standard this approach can be a solution.
filter_policy = jsonencode({
type: [ "order.received" ],
data: {
version: [ "v1" ]
}
})
Versioning:
In software, the versioning often is defined as the Semantic version, This is important when maintaining the software code versioning, model versioning and documentation versioning internally within the boundaries of capability.
But getting in communication boundaries the Minor and Patch parts of a version can have no interest on the consumer side in runtime but can be interesting as an informative context. As here our usage relies on the runtime and consumption we exclude the Minor and Patch part of the version.