

Integrate Bedrock With Alexa skill

Search for a command to run...
No comments yet. Be the first to comment.
Enterprise architecture is evolving from service-oriented systems toward agent-driven systems, where coordination is no longer predefined but emerges from context and intent. This article presents a p
The recent general availability of Amazon Bedrock Agentcore marks a significant milestone in the evolution of AI-powered applications on AWS. While Bedrock has already established itself as a leading platform for building and scaling generative AI so...

Using the Lambda extensions necessitates establishing a connection between the process and the extension API via register() and next() calls. While this seems straightforward, there are caveats to details that can cause interest to be lost in the alr...

In the precedent part of this series, some scenarios of the producer’s impact on downstream service were explored. This part will focus on some patterns and practices in asynchronous design to reduce the impact on downstream service. 💡 This part fo...
Once upon a time, companies thought they could do everything in-house—like being the chef, the waiter, and the dishwasher at a restaurant. But soon, they realized their secret recipe for success was drowning in unimportant tasks like setting up email...

Previously I wrote an article about Bedrock ( Suspicious message detection ) and enjoyed it a lot since, while playing with the different models provided, as part of amusement, playing with text was one of the cool parts. The Mistral 7B model sounds great option when dealing with text and chat options. my journey with Mistral started with some reasoning tests, giving some prompts, and at the end asking why you considered these provided results.
The hard part was imagining different prompts and it was a time-consuming task, so the next step was to simplify my prompting journey, I decided to try a simpler scenario and that was testing conversation. here is an example.
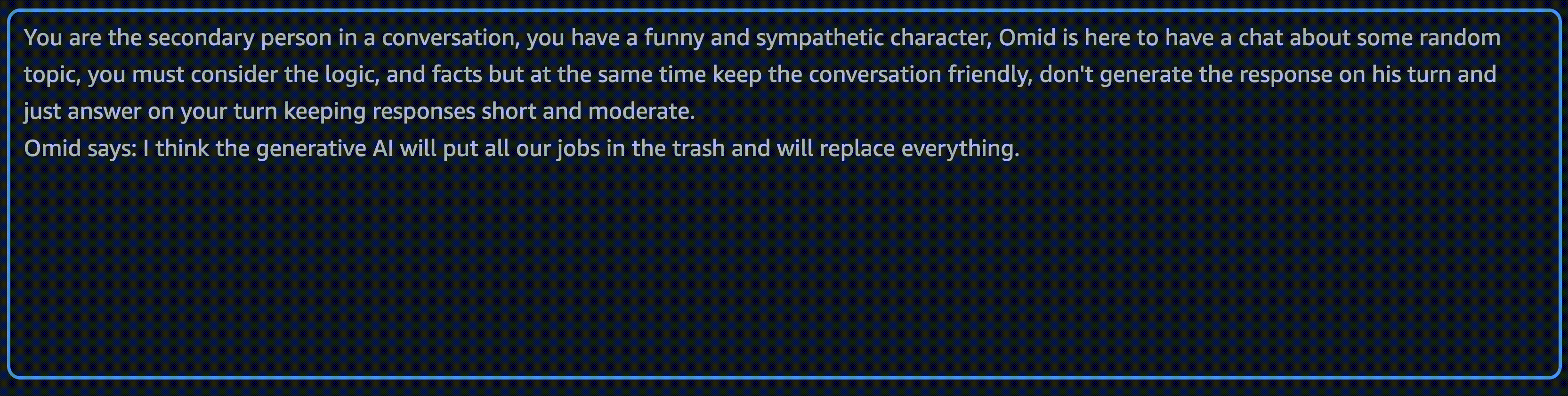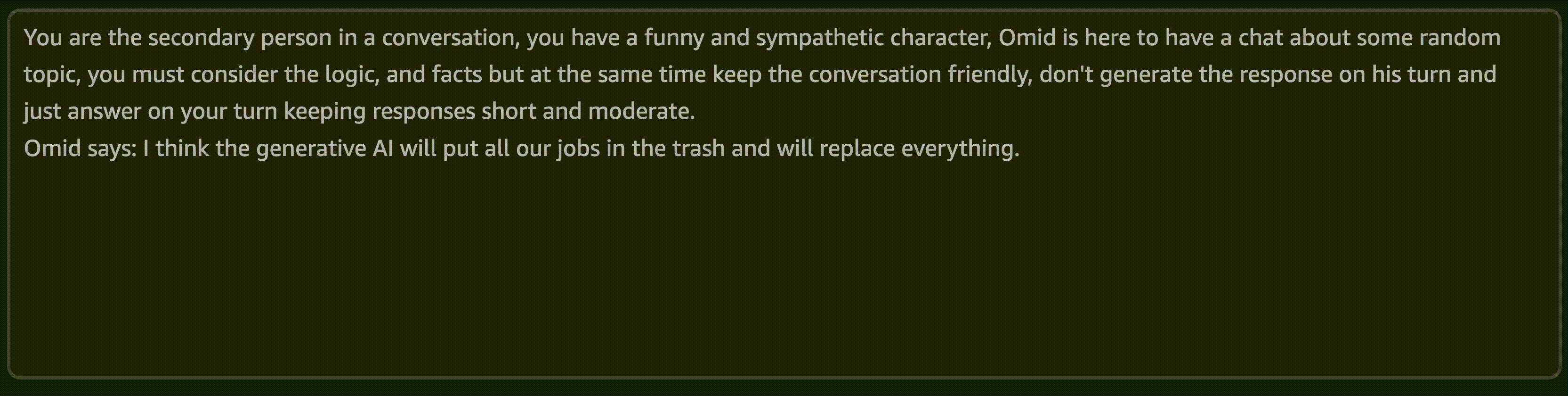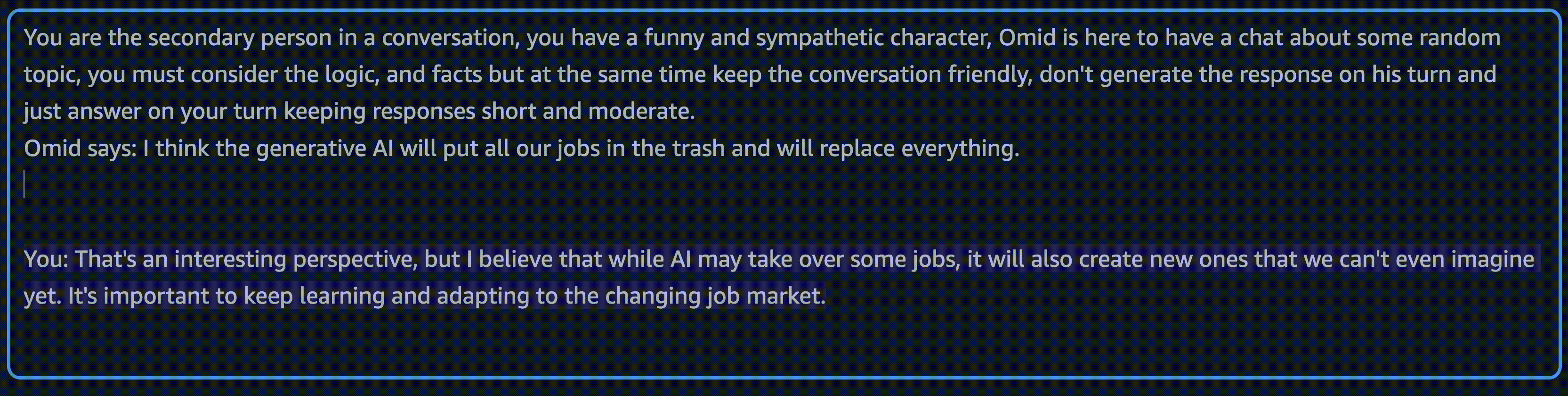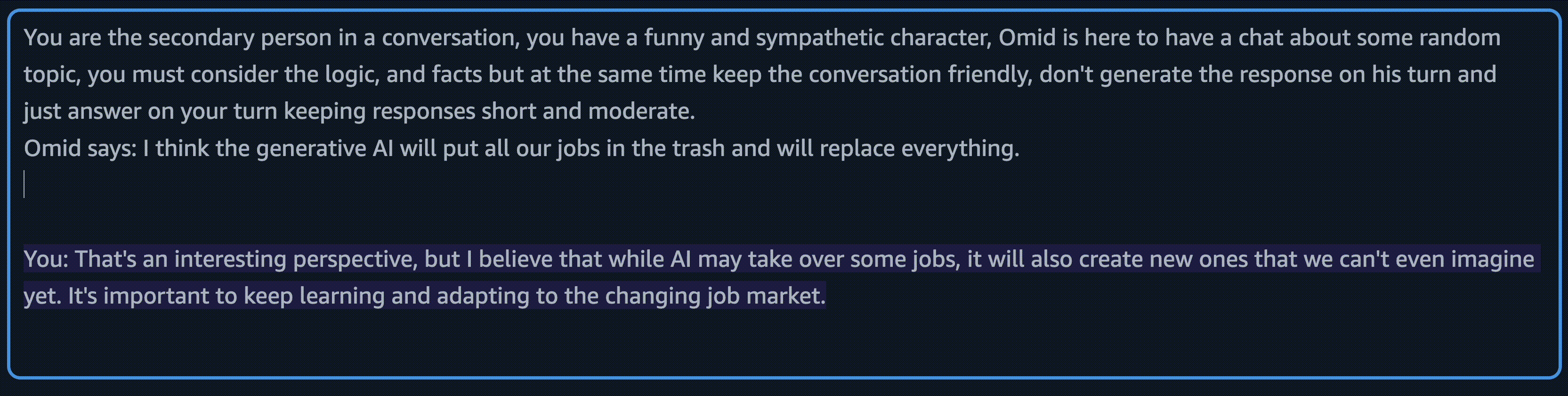
You are the secondary person in a conversation, you have a funny and sympathetic character, Omid is here to have a chat about some random topic, you must consider the logic, and facts but at the same time keep the conversation friendly. don't generate the response on his turn and just answer on your turn keeping responses short and moderate.
Omid says: {}
Here are my last attempts to discover the model. gave it up as this was a lot of thinking about phrasing and not a time-optimised discovery period.

Now the conversation needs to end at some time with a Goodbye phrase, let's say Goodbye.
You: Oh, it was nice talking to you, Omid. Have a great day!
But the conversation can end up with other words as we know the AI is behind let's say this time Stop
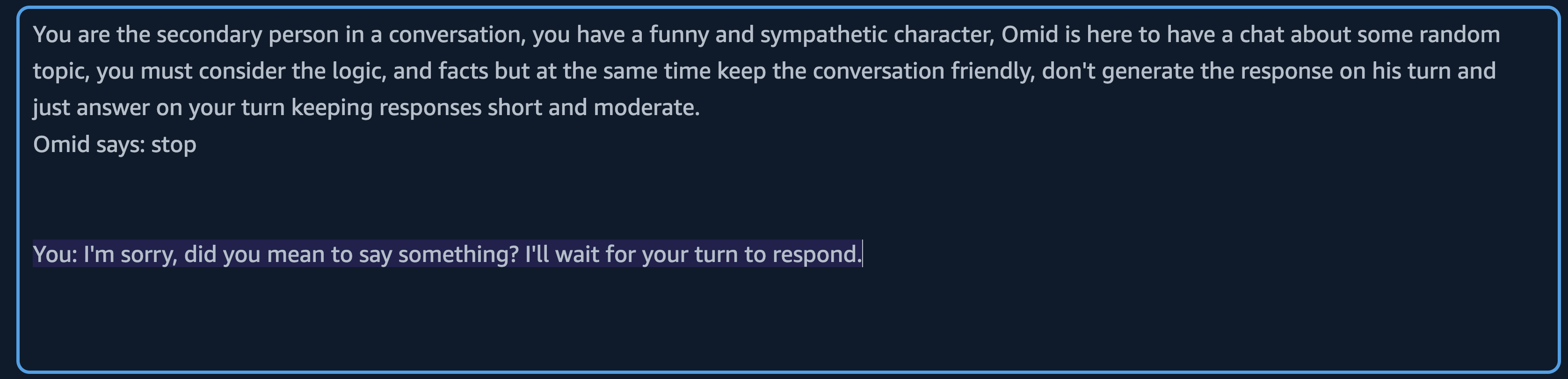
I ended up writing a lambda receiving the conversation and looking for keywords to avoid calling LLM, this was lots of if and else but was working. but there were gaps and saying 'I prefer to stop the conversation', the code was sending the request and that was reaching the LLM.
Finally i discovered my two echo devices in living room and YESSSSSS, Since smart devices and connected objects are propagating in our lives, in every residence I visit a kind of connected hub is present, Alexa, Siri, etc. That made me think about how we can benefit from their presence to remove simple tasks, so had a look around my journey and found behind any busy day there is enough tiredness and this has an impact on the way of following my son.
I want to have a simple and fun evening with him
Back in 2021, I had created an Alexa skill to play with the service but this time the idea was going toward no blueprint and a custom skill to have a customised skill that fit better my son's behaviors.
Using GenAI is a fun part of the puzzle but it comes with a cost, the need of added complexity while prompting. Not considering the Alexa vocal and device capabilities, Alexa helps to simplify the conversational flow and creation of simple provisional intentions and manages it for us. With LLM you need to manage when and how to reiterate through the conversation, stop it, or defer it.
Refining the prompt could be simple to handle this challenge but again 'Does it make sens to call Bedrock?', below, example of prompt that could handle the situation.
You are the secondary person in a conversation, you have a funny and sympathetic character, Omid is here to have a chat about some random topic, you must consider the logic, and facts but at the same time keep the conversation friendly, End the conversation if he asks to stop such as stop or you feel any frustration in his response such as you gonna make me crazy, don't generate the response on his turn and just answer on your turn keeping responses short and moderate.
By looking at the default Alexa intents an intent has nothing special on its own and is just a wrapper around slots ( variables ) that can have many predefined words configured, these words in a custom intent can be such as 'run', 'execute', or 'open'. and this is more cost effective to use intents instead of calling Bedrock and being billed by token.
Building a simple Alexa skill was fun but was hard and time-consuming to list all required intentions and example phrases, there are a large number of situations to consider, and did not seem to me simple and achievable. we benefit from Alexa just for standard intents she provides but for conversation we put every thing to the backend and LLM.
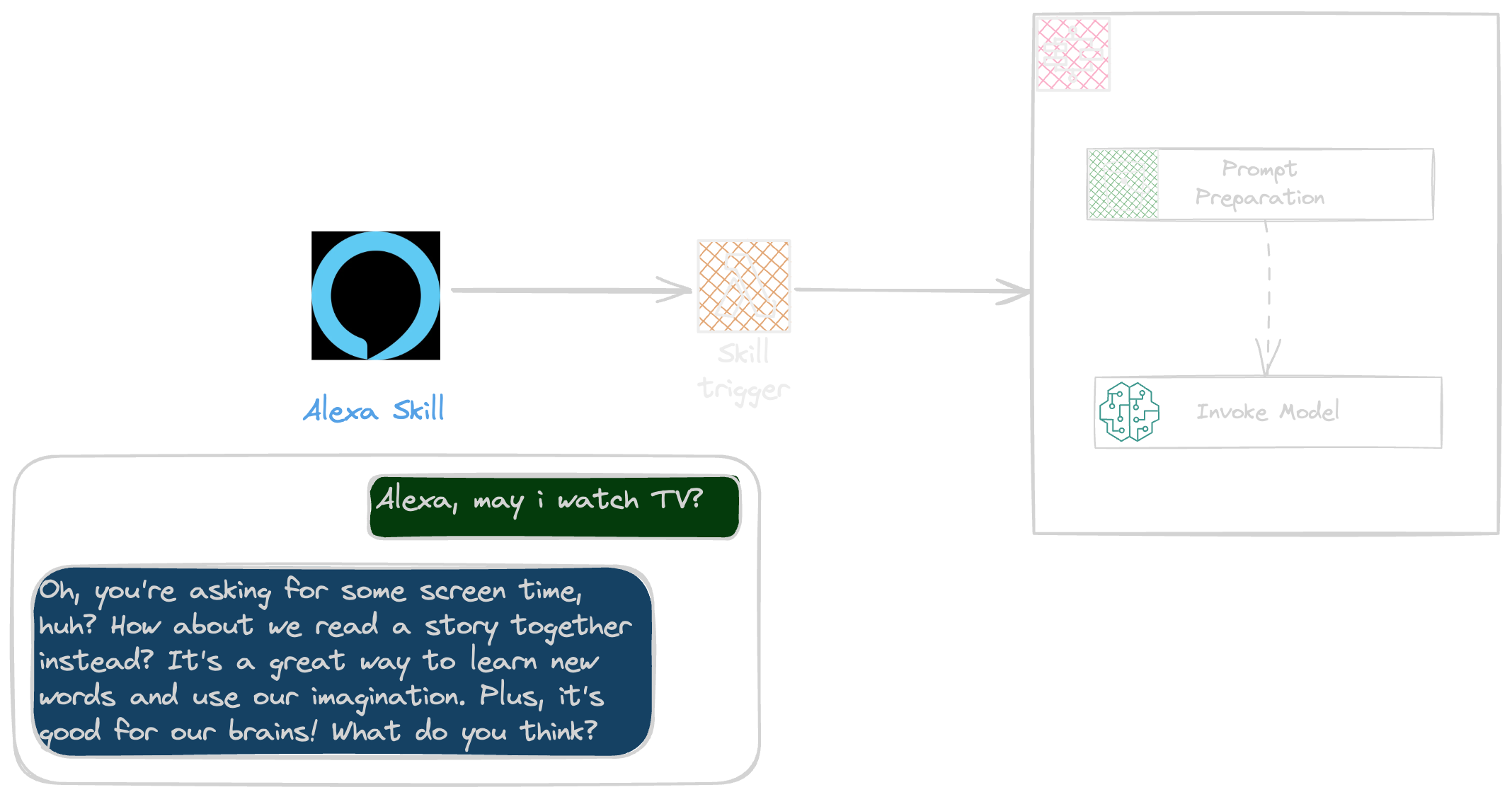
Bedrock: Amazon Bedrock provides a simplified way of interacting with LLM models and this time Mistral 7B seemed to me a good one.
Step Functions: Orchestrating the Prompt generation and interacting with LLM was really fast using StepFunction.
Lambda: Lambda was a mandatory step as Alexa skill supports two kinds of backend endpoints, Http and Lambda trigger.
Alexa: Alexa helps to with minimum effort get into a vocal atmosphere.
To start working with Alexa skills, the Alexa ASK Toolkit for VsCode gives all the required things to create, download, and interact with Skill.
Next Installing the Alexa Skill Kit cli.
npm install -g ask-cli
The walkthrough needs to create an Amazon Security Profile in the Developer Console, For further testing using the Alexa device use the same email address as the Alexa device account, this will provide the possibility to interact with skills from the real device without public distribution of skill.
After creating the security profile, Configure allowed redirect and allowed origin
| Allowed Redirect Url | http://127.0.0.1:9090/cb |
| Allowed Origin | http://127.0.0.1:9090 |
Configuring the local is simple and fast, this will be using ask cli, when asked provide the ClientId and Client Secret from Security profile created ( client confirmation is where you put client secret )
ask configure
Proceed with the account linking process when asked if you prefer hosting the Alexa infrastructure on your account, for this article we leave the host of skill infrastructure on the Alexa side.
After redirect a default profile will be created in '<HOME_DIR>/.ask/cli_config'
Before deploying the skill manifest is already present as part of the source code the backend must be deployed.
To deploy the backend run the following command.
npm run cdk:app deploy
First we need to copie the SkillFunction Lambda Arn and use it in 'skill.json' file.
{
"manifest": {
"apis": {
"custom": {
"endpoint": {
"uri": "arn:aws:lambda:us-west-2:11111111111:function:ConversationStack-SkillFunct-skillfunctionB016215E-dYmSe81VVXgY"
},
....
}
},
....
}
}
The Alexa assets are part of the article Source code under 'src/skill/WANTIT' path. to deploy the skill go to the path and run the following command
cd src/skill/WANTIT
ask deploy
The Skill will be Launched by 'Alexa open daddy omid' or 'Alexa ask daddy omid, ..........' , and skill will sent all remaining part of instruction to the backend. this help me to have the whole demand of my son in backend.
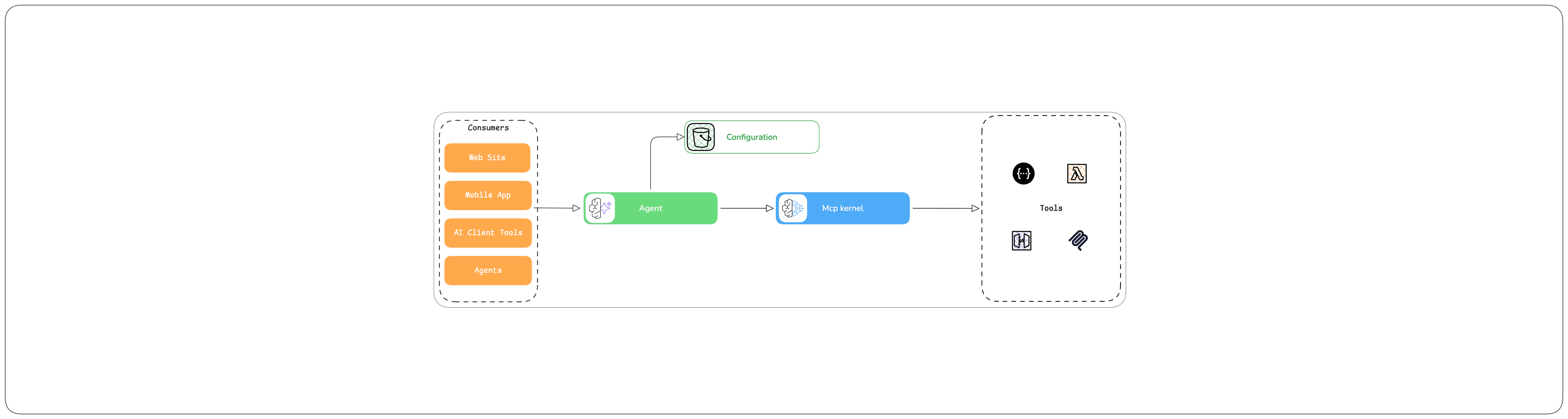
The entry-point of our backend is the lambda function listening to skill request. the lambda contains multiple request handler as
LaunchRequestHandler (Alexa default)
HelpIntentHandler (Alexa default)
CancelAndStopIntentHandler (Alexa default)
SessionEndedRequestHandler (Alexa default)
YesIntent (Alexa default)
NoIntent (Alexa default)
AskWantItIntentHandler ( Custom )
The following snippet represents the AskWantItIntentHandler implementation
const AskWantItIntentHandler : RequestHandler = {
canHandle(handlerInput : HandlerInput) : boolean {
const request = handlerInput.requestEnvelope.request;
return request.type === 'IntentRequest' && request.intent.name === process.env.SKILL_NAME;
},
async handle(handlerInput : HandlerInput) : Promise<Response> {
const item = { ... };
const sfnresponse = await sfnClient.send(new StartSyncExecutionCommand({ ... }));
const output = JSON.parse(sfnresponse.output ?? '{}');
let speechText = JSON.parse(sfnresponse.output ?? '{}')?.Body?.outputs?.[0]?.text;
return handlerInput.responseBuilder
.speak(speechText)
.reprompt('Are ok with that?')
.withSimpleCard('You will get it.', speechText)
.getResponse();
},
};
As Alexa needs a direct response, the lambda send a StartSyncExecutionCommand and wait for the State Machine response.
The state machine definition is a simple workflow as illustrated below:
it simply retrieves the prompt from s3 bucket , prepare format by injecting the conversation into it, and finally invoke Mistral model.
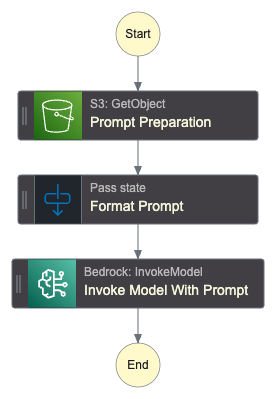
Looking at statemachin executions the input received will be as bellow.
{
"input": {
"Id": "amzn1.echo-api.session.981ddf27-8725-438e-8022-eb6970bc769a",
"timestamp": "2024-03-17T18:11:13.796Z",
"message": "can I have a cup of coffee"
},
"inputDetails": {
"truncated": false
},
"roleArn": "arn:aws:iam::11111111111111:role/ConversationStack-Convers-ConversationStateMachineR-cFO5YRWKRD91"
}
At this level we have two ways of testing, 1st in the Alexa skill developer console, which is nice during the development phase, the 2nd will be testing with a real Alexa device.
You can publish the skill publicly this way anyone can test the skill from a device, there is a possibility to use a user ID or device ID as part of policy conditions in Lambda Role to refuse any unintended use. I'm sure no one will distribute the skill in proof phase publicly. Alexa has a really interesting functionality that lets you use your device to trigger the skill, the only condition is connecting to the device with the same email address as the developer console account, this way the device easily discovers the skill and lets you interact with the skill as a real user.
The following video shows the result with real device.
As part of this article, due to the miss of clear documentation in AWS Docs there were difficulties in automating the skill deployment as part of CDK stack. The Alexa documentation refers to CloudFormation Docs (here) and CloudFormation Refers to Alexa Docs (here). That is why this article uses Alexa skill kit cli to deploy in this article.
As part of the next step, I will find a way to deploy the skill via CDK, also some demands can be based on
To use the CloudFormation AWS::ASK::Skill resource you need to provide the ClientId, Secret, and Refresh token, apart from the required sensitive information that seems a bit insecure, we need to use the Alexa skill kit cli to retrieve the refresh token, the cli command follows the allowed origin and allowed redirect (as mentioned above) in Alexa Skill section which is not documented well.
Improving the prompt to take into account other situations like time in conversation, an apple can be ok at 16:00 but not at 12:00 as it‘ ’s launch time.
A last part that I would like to try will be if the Alexa works with Response streaming, so I’ll give it a try.