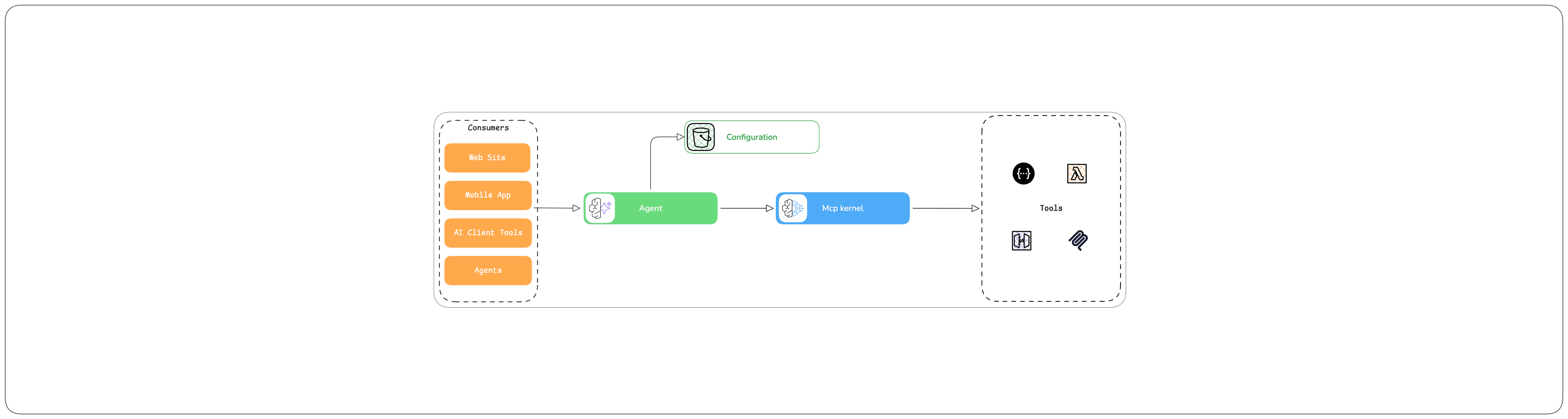
AWS Step Functions Distributed Map
The AWS Serverless ecosystem had a lot of power for a longtime and AWS StepFunctions was for a significant years part of. The decomposition of a big system is a golden concept of design where any single component brings a value and that collaboration gives the real meaning to all those components. The choreography is a way of collaborating but it s not the best fit for all cases as we need to collaborate in an orchestrated manner and a coordinator pattern need to be the center of that system to achieve an optimised collaboration. AWS StepFunctions is part of Serverless ecosystem that helps achieve that desired coordination.
But StepFunction is not today just a Serverless orchestration service and let to achieve more significant results in different distributed scenarios. By the release of Distributed Maps, it became a good fit for distributed data manipulation like large files ( JSON, CSV ) or files in an S3 bucket.
Distributed Map
In general words , the way distributed map works is by dividing a large asset into chunks and let them be treated in isolation and simultaneously.
In technical words, Distributed map parallelize the treatment of batch of items in isolation logical contexts called child workflow executions. This isolation also helps to control in isolation the errors that any batch of items can encounter during treatment.
Distributed map helps control the collaboration between different services via refined configurations like MaxConcurrency.
Configuration
Some useful configuration to understand are explained here but to have a better understanding i recommend to refer to the AWS Documentation
MaxConcurrency: maxConcurrency( default 1000 ) is a mean to specify the number of concurrent child workflow executions that can be executed simultaneously.
ItemReader: This config indicates the source of dataset that the distributed map must use to fetch the data. this can be a S3 bucket, A CSV or a JSON File.
ItemBatcher: You can define the Max number of items or Max Bytes of Input Distributed map passes to each child workflow execution.
ItemProcessor: The configuration that represent the workflow definition and states of workflow to treat the batch of items as well the ProcessorConfig to indicate the type of StateMachine being STANDARD or EXPRESS and The mode.
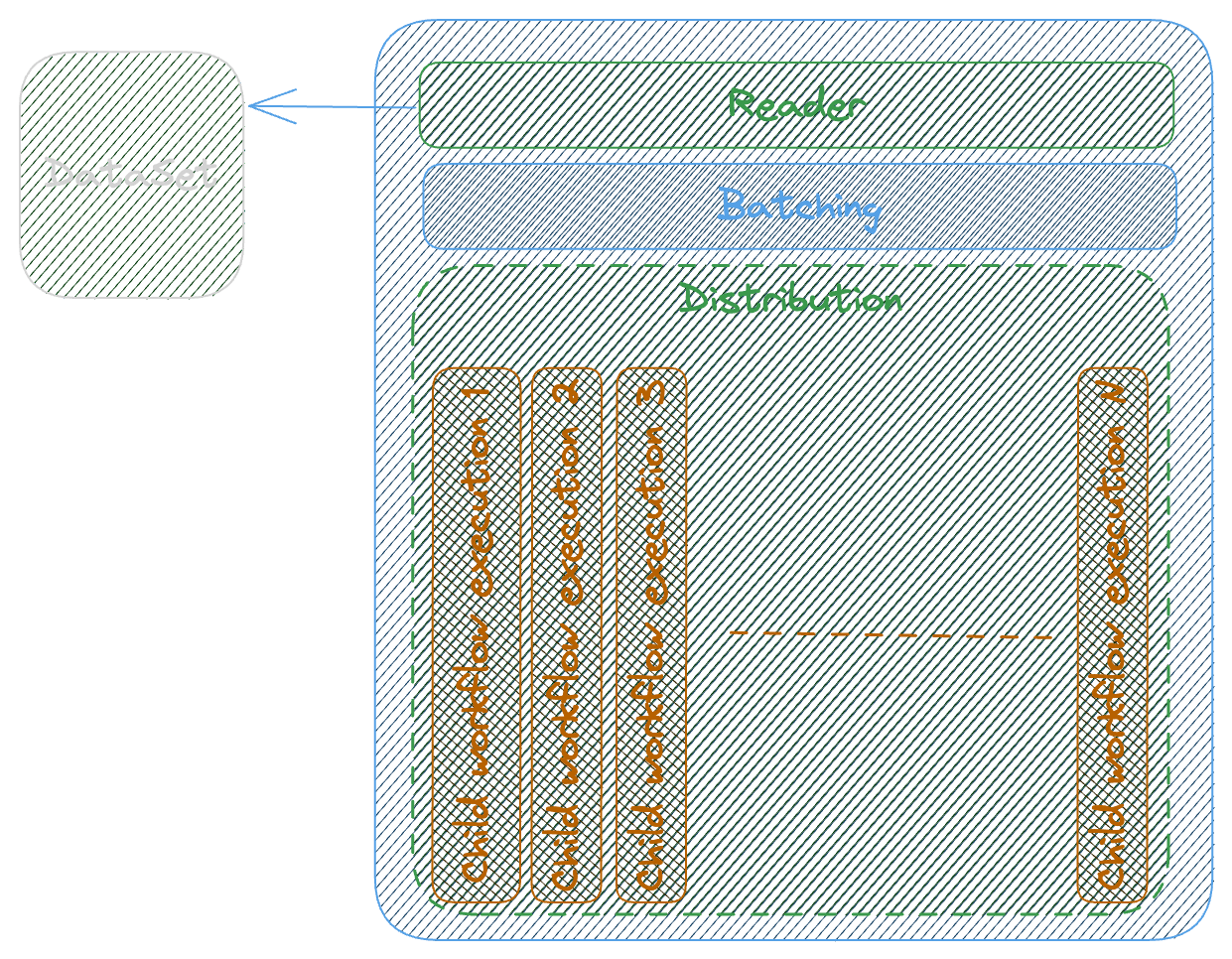
How distribution works
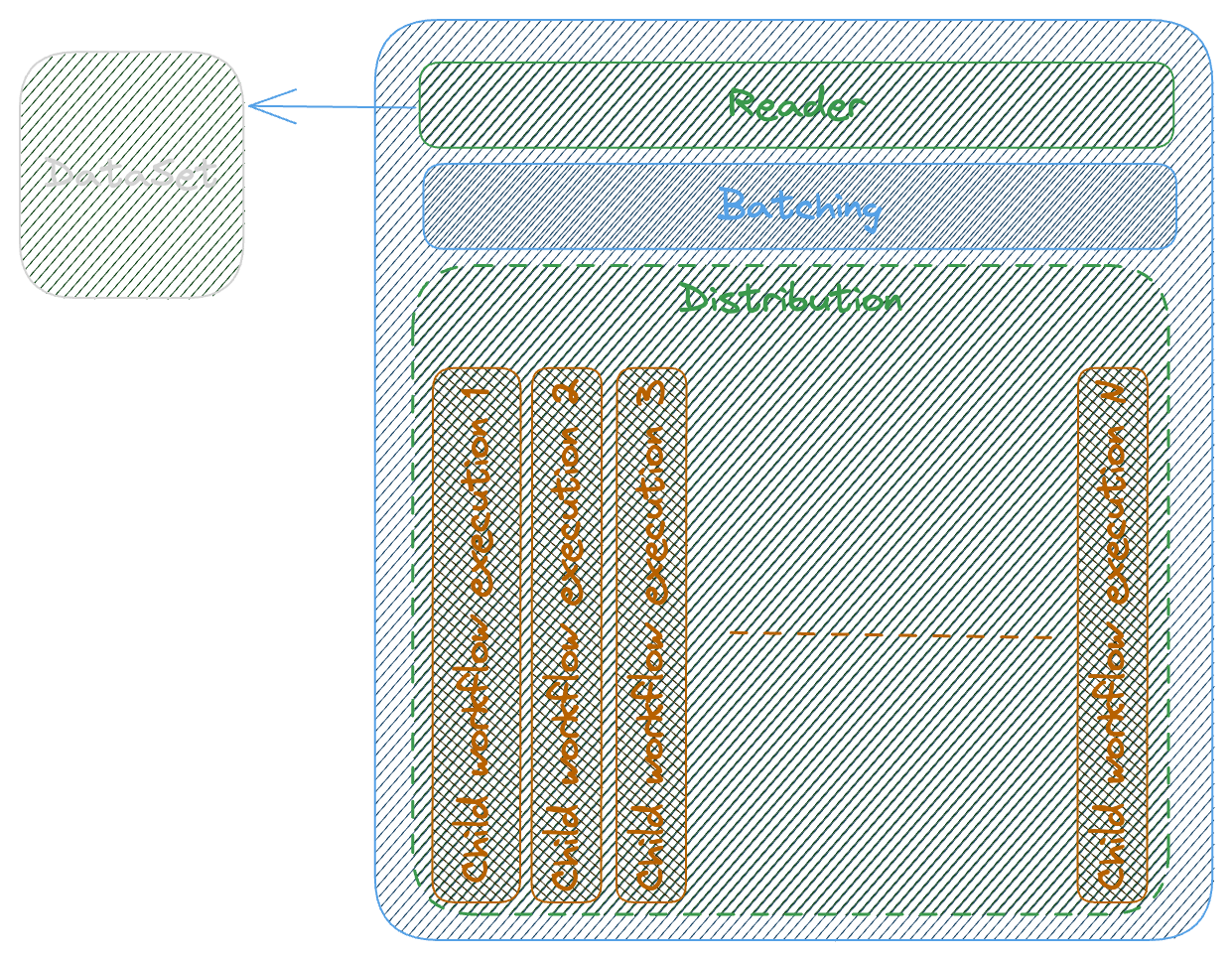
Reader Reads the DataSet per ItemReader config
Batching Batch data to array of items per ItemBatcher config
Item Processor Distribute the batch sets of items and execute the child workflow executions giving a batch of items as input.
You can configure Item Selector and Result Writer , to lean more about refer to Documentation
Map Run resource
Map Run resource behaves as a coordinator for Child Workflow executions by coordinating following details.
Concurrency
Batching
Keeping Track of Child execution States
in Practice when you define MaxConcurrency or MaxItemsPerBatch as in our example, the Map Run associate items by assuring that the Batch Size does not bypass the 256 KB and based on batching possibilities allocates concurrent child executions.
Try it on your own
This article source code is publicly accessible here, If you would like to try the examples and different patterns follow the instructions in README.md file in this repository
Using Simple Distributed Maps
In this example we read a large number of files for a s3 bucket ( 65K Json objects of 200KB ) and will look in details how the workflow behaves.
The parent DISTRIBUTED map configuration has following details
| Configuration | Value |
| MaxItemsPerBatch | 5000 |
| MaxConcurrency | 10000 |
The INLINE map configuration ,inside the parent Distributed map, has following details
| Configuration | Value |
| MaxConcurrency | 40 ( Max Recommendation ) |
The Example will be as illustrated in the following figure
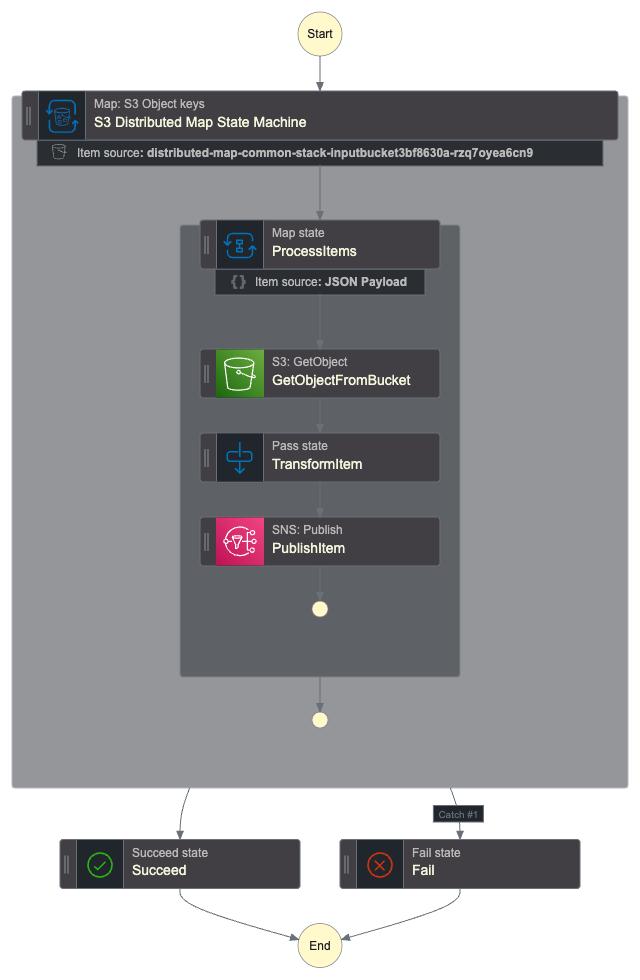
Running this example longs around 10 minutes and will result a failed status after that time due to history limit of 25000 ( hard quota ) .


Changing the batching MaxItemsPerBatch configuration is one of the most straight forward solutions to this limitation. After setting the MaxItemsPerBatch to 1000 items the process same s3 objects will result a success status with a duration of 05:40.531 ( 5.5 Minutes ).

This result can reasonably cover a variety of scenarios but for scenrios with large amount of data can take a long time and does not seem the best fit in term of operation, performance and requirements.
Using Nested Distributed Map
In this example, the configuration is partially same as before , we read a large number of files for a s3 bucket ( 65K Json objects of 200KB ), the only difference is that for Chile Workflow execution is encapsulated in a second ( Nested ) Distributed Map to add a second level of parallelism at batch level.
The parent DISTRIBUTED map configuration has following details
| Configuration | Value |
| MaxItemsPerBatch | 5000 |
| MaxConcurrency | 10000 |
The Nested DISTRIBUTED map configuration has following details
| Configuration | Value |
| MaxItemsPerBatch | 50 |
| MaxConcurrency | 1000 |
The nested INLINE map configuration has following details
| Configuration | Value |
| MaxConcurrency | 40 ( Max Recommendation ) |
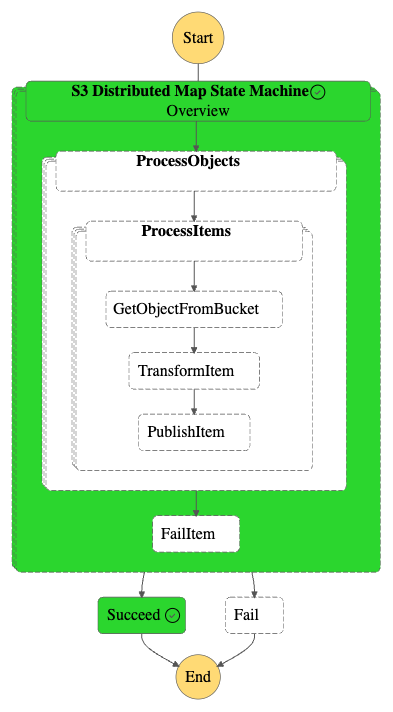
The Example will be as illustrated in the following figure

Running an execution create a first Map Run resource ( More info here )
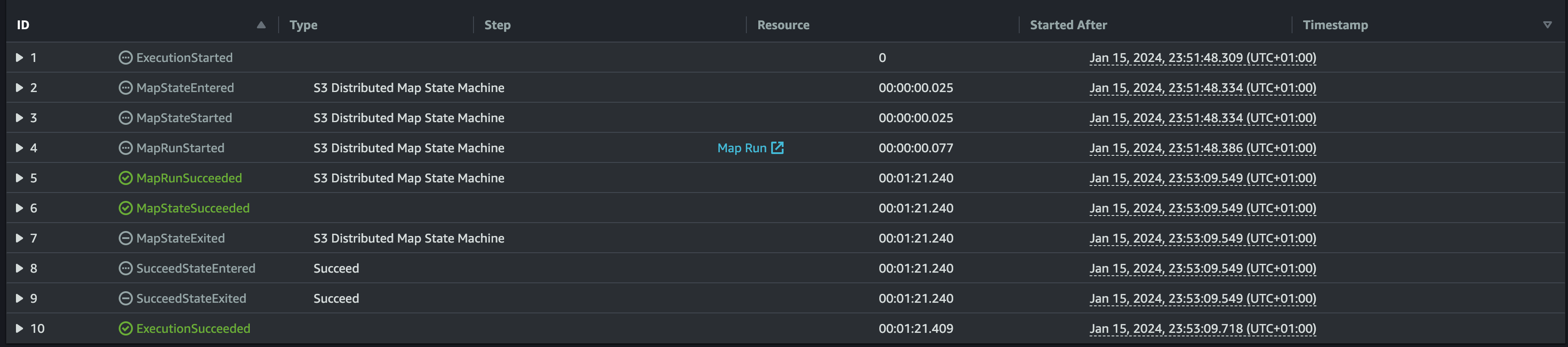
Looking at Map Run resource, there are a listing of executions, each with a Batch of Items as below.

In this example looking at any single execution with around 1800 items, the execution is a nested distributed map by its own. by this example we create a Top Down Distributed Map hierarchy at 2 level.
Here an example of what looks a child execution with a workflow State containing an INLINE Map State.

This Nested Distributed Map also has a listing of second level child workflow executions but this time with limited Items per Batch around 50 for each execution.
This seems a reasonable situation to be treated by INLINE Map ( Limited concurrency and History quota )

Looking at this execution list all executions, the start and end time of executions are approximately close showing the parallelism and resulting a close execution duration ( in our example around 2 minutes ) and looking at the Parent Distributed Map durations we notice the same.
The Execution ran for a duration of 01:20:959 (1.5 Minutes) with a success result.

Conclusion
Distributed map is a great feature and shows off well the power of AWS Step Functions. The Distributed Map can be used in a variety of situations when the need of performance , simplicity and process isolation can be a concern.
In this article we could achieve a better understanding while processing amount of data in a scalable , reliable and performant manner.